Porting between different processor architectures
From HP-SEE Wiki
Porting from Cell B.E. to hybrid X86 and GPGPU
EagleEye
Section contributed by UPB
The detection algorithms that are implemented in the EagleEye framework were originally implemented on the Cell B.E. architecture. They performed rather well, but given the limited life-time of the Cell B.E. architecture, we decided to port those implementations toward efficient hybrid X86-GPGPU versions. To this end, we are currently working on the modification of the Gaussian filter used in the Canny Edge Detectorm as well as the Hough transformation to dynamically adapt some of the previous hard coded parameters with respect to image content. At present we are working with a MPI - POSIX Threads implementation, while a GPGPU port is ongoing.
Our current parallel infrastructure (using MPI and POSIX Threads) is based on splitting the work nodes into two entities: a coordinator which has the task of distributing work and masters who are responsible of the actual image processing. A master has a work manager thread and a number of slaves that do the actual processing. A diagram describing an example of our parallel infrastructure is presented in the following picture
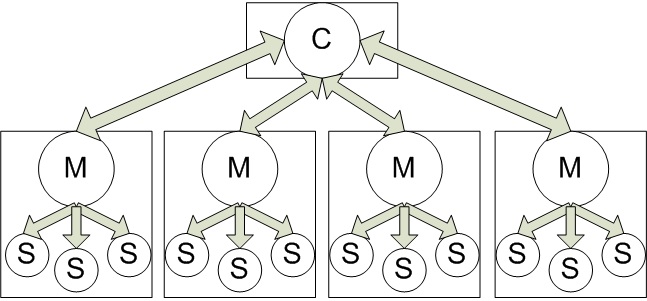
We have a single entity that controls work distribution in the system: the coordinator. The coordinator scans the folder passed as input from the disk and loads into memory the paths for all the jpeg files in finds. Communication between the coordinator and the masters is done in a client - server fashion where the masters ask for work and the coordinator responds with either a file path or a quit message if there are no more files to process. Communication between the coordinator and the masters is done using the synchronous MPI primitives MPI Send and MPI Recv. The coordinator is run alone on a separate machine (there no slave threads doing processing on the coordinator machine). We felt this was a suitable approach since allowing the coordinator to also server the functions of a master would have significantly increased code complexity (using asynchronous communication instead of synchronous, managing both the global work queue and the local work queue) and might have caused delays in responding to the requests from other masters.
The masters have two primary functions: fetching work from the coordinator and managing the slaves. The slaves and the masters communicate in a producer - consumer fashion through a queue in which the masters add work and the slaves remove work from the queue and do the actual processing. The masters try to maintain the queue full at all the times so that the slaves don't have to wait during the master - coordinator communication. When a slave retrieves an element from the queue the master immediately sends the coordinator a message requesting more work. During the time the master is processing the work it took from the queue the coordinator refills the queue. The queue has as many elements as there are slaves.
The slaves have the only function of processing the images. They retrieve work from the local queues managed by the masters and apply the processing algorithms to the corresponding images. When a quit command is retrieved by a slave thread from the work queue that thread finishes its execution.
Porting from X86 to PowerPC
Section contributed by IICT-BAS
The main issue when porting an application from x86 to PowerPC on Blue Gene/P is to ensure support for all the required libraries used in the application. It is important to remember that compilation for the Blue Gene/P is essentially cross compilation. This means that the target architecture is not equal to the architecture of the host (usually the front-end node). In our case the front-end node is running SUSE Linux, while the target compute nodes are running IBM proprietory Compute Node Kernel (CNK) operating system. This means that one must not use the libraries available for the host architecture, but aim for the libraries that are installed in other locations. This process is simplified by the module framework, explained elsewhere in this guide, which enables required libraries to be loaded as modules, before running the configuration script. The necessary compiler and linker directives can be obtained in this way. Another alternative, which is used widely, is to use the pkg-config system. However, if the required library is not particularly popular, the user can install it in their home directory and provide the necessary flags during compilation. Currently most of the software required by HP-SEE applications is available on the Blue Gene/P, as well as many of the popular libraries for writing scientific code. When porting their own codes, users must take into account that the target architecture is big endian 32-bit. This means that data stored in binary format on disk will not be directly readable on an Intel machine and also that care should be taken if such data is transformed over the the network. Once the developer is aware of this feature, transformation of data is essentially trivial and is directly supported in popular environments for scientific computing like Matlab.